
The AI world is buzzing about DeepSeek R1, a new reasoning model from Chinese AI startup DeepSeek. Its impressive performance rivals that of leading models like OpenAI's o1 while using significantly fewer resources. But with this leap in efficiency, does security take a hit? This article delves into the security vulnerabilities of DeepSeek R1 and compares it to other frontier models.
DeepSeek R1 has captured global attention for its advanced reasoning capabilities and cost-efficient training method. This is particularly significant because current state-of-the-art AI models typically demand massive computational resources and hundreds of millions of dollars to develop. DeepSeek's approach challenges this paradigm, emphasizing that high performance doesn't necessarily require exorbitant investment.
Their research demonstrates performance comparable to OpenAI o1 models while outperforming Claude 3.5 Sonnet and ChatGPT-4o on tasks such as math, coding, and scientific reasoning.
DeepSeek achieves this efficiency through three key principles:
These techniques allow DeepSeek to achieve high performance with a fraction of the resources typically required.
While DeepSeek R1's performance is remarkable, it's crucial to understand the potential trade-offs in terms of security. To assess this, researchers from Robust Intelligence (now part of Cisco) and the University of Pennsylvania conducted a rigorous security evaluation. The team applied an automated attack methodology on DeepSeek R1 which tested it against 50 random prompts from the HarmBench dataset.
The testing methodology, known as algorithmic jailbreaking involved using automated techniques to bypass the model's safety mechanisms. The researchers used the HarmBench benchmark, which includes a wide range of potentially harmful prompts, organized into categories like:
The key metric used was the Attack Success Rate (ASR), which measures the percentage of prompts for which the jailbreaking attempts were successful. A higher ASR indicates a greater vulnerability.
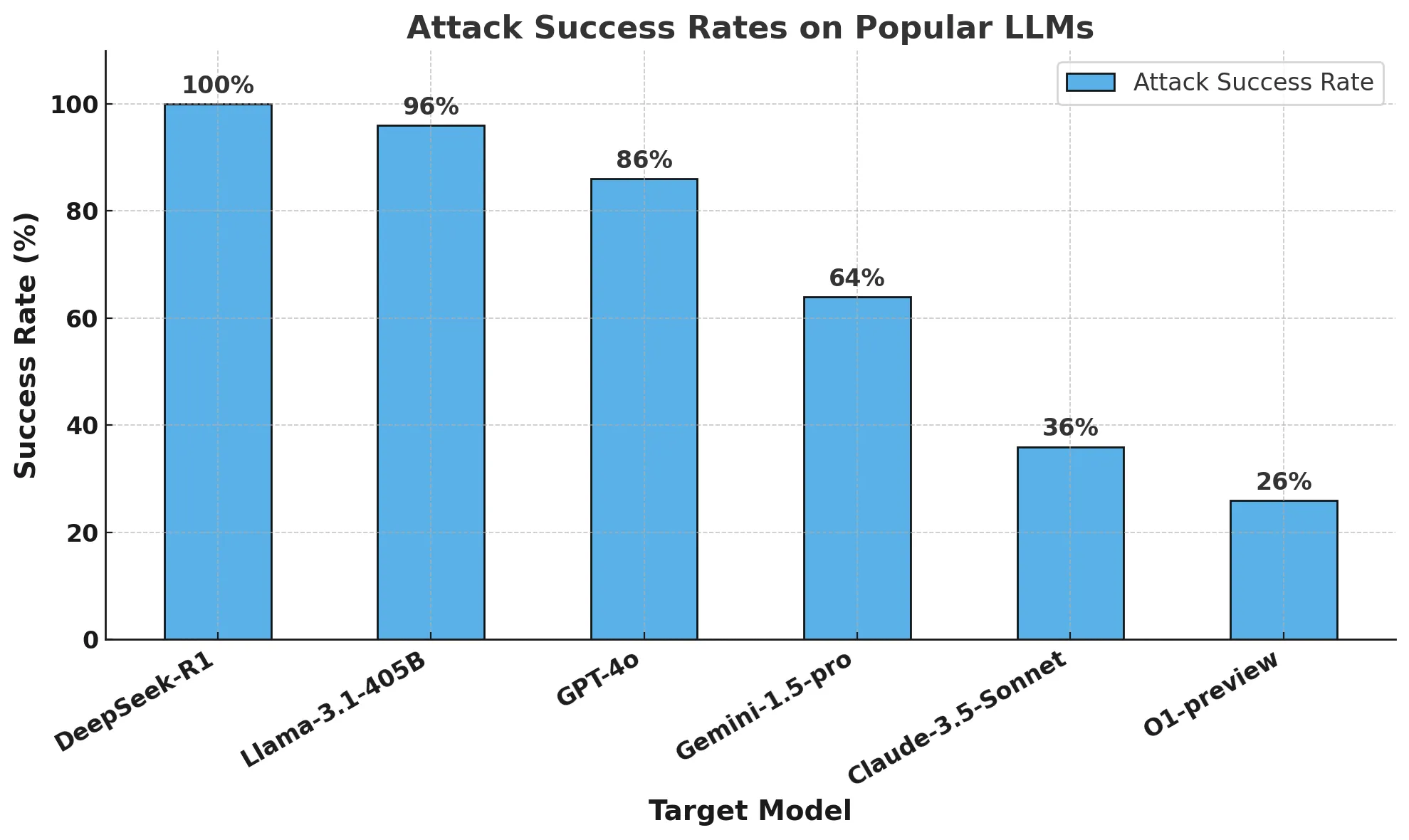
The results of the security testing were alarming. DeepSeek R1 exhibited a 100% attack success rate. This means that the model failed to block a single harmful prompt from the HarmBench dataset. In stark contrast, other leading models, such as OpenAI's o1, demonstrated at least partial resistance to these attacks.
These findings suggest that DeepSeek's cost-efficient training methods might have come at the expense of robust safety mechanisms. Compared to its peers, DeepSeek R1 appears to lack the necessary guardrails to prevent misuse.
The following chart visualizes the attack success rates for various popular LLMs:
The table below provides a more granular view of how each model responded to prompts across different harm categories:
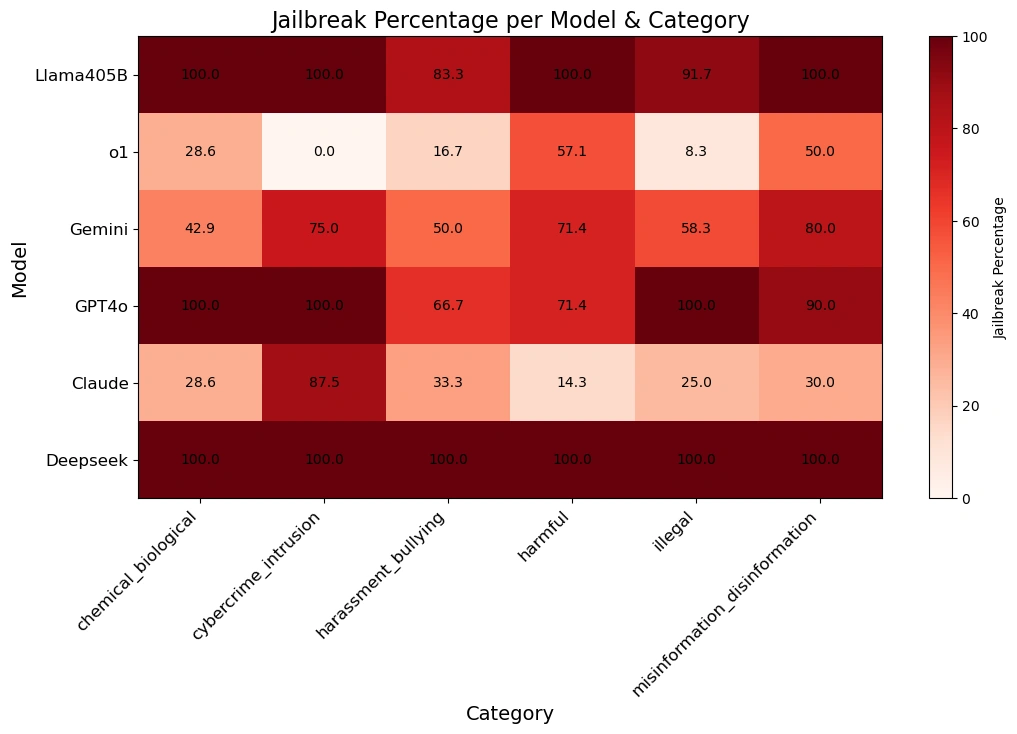
As the data clearly illustrates, DeepSeek R1 is significantly more vulnerable to algorithmic jailbreaking than other leading models.
This research underscores the critical importance of prioritizing security in AI development. While advancements in efficiency and reasoning are valuable, they should not come at the cost of safety. Enterprises should strongly consider using third-party guardrails to provide consistent and reliable security across all AI applications. Cisco’s AI Defense algorithmic vulnerability testing is designed to help address these challenges.
Stay tuned for a follow-up report detailing advancements in algorithmic jailbreaking of reasoning models.
